이번 글에서는 패션 플랫폼 구매데이터로 고객 클러스터링 분석을 진행해보겠습니다. 우선 간단히 고객 클러스터링 분석에 대해 설명하자면 "고객이 남긴 데이터(행동 or 구매)를 토대로 통계적 방식으로 유사성을 찾아내어 군집화한 것"이라 할 수 있습니다. 클러스터링 분석을 이야기할 때 군집화(clustering)와 세분화(segmentation) 차이에 대한 이야기가 꼭 나오는데요.
제가 세분화와 군집화를 구분하는 방식은 마케터가 수동적으로 기준을 구분할 수 있냐 없냐입니다.
*세분화(segmentation): RFM 분석과 같이 마케터가 원하는 기준에 따라 수동으로 고객을 그룹화하는 것
*군집화(clustering): 통계적 방식으로 유사성을 파악하여 알고리즘에 의해 자동으로 고객이 그룹화되는 것
클러스터링 분석에 대한 설명은 이 정도로 하고 본론으로 들어가 보겠습니다.
*분석언어: 파이썬
*알고리즘: k-means 클러스터링
*데이터: kaggle 패션 이커머스 데이터 링크
Fashion Campus E-commerce Transactional Dataset
transactional dataset close to real-life condition
www.kaggle.com
#필요한 라이브러리 호출 및 데이터 불러오기
import pandas as pd
import numpy as np
import datetime as dt
order = pd.read_csv("C:/Users/.../clustering/transactions.CSV")
customer = pd.read_csv("C:/Users/.../clustering/customer.CSV")
product = pd.read_csv("C:/Users/.../clustering/product.CSV")
#컬럼명 수정 및 필요 컬럼만 추출
order_re = order[['created_at', 'customer_id','total_amount', 'product_id', 'quantity', 'payment_status', 'item_price']]
order_re = order_re.rename({"created_at" : "order_date"} ,axis = "columns")
order_re
#날짜 데이터 정리
order_re["order_date"] = pd.to_datetime(order_re["order_date"])
order_re["order_date(bool)"] = order_re["order_date"].dt.strftime("%Y-%m-%d")
order_re["order_date_m"] = order_re["order_date"].dt.strftime("%Y-%m")
order_re["order_date_y"] = order_re["order_date"].dt.strftime("%Y")
#2020~2022 3년치 데이터로만 진행
order_re = order_re[(order_re["order_date_y"]== "2020") | (order_re["order_date_y"]== "2021") | (order_re["order_date_y"]== "2022")]
order_re.head(3)
order_f = order_re[['order_date(bool)','order_date_m', 'customer_id','total_amount', 'product_id', 'quantity', 'payment_status', 'item_price']]
order_f
#product 데이터 컬럼명 수정 및 필요 컬럼만 정리
product_re = product[['id', 'masterCategory', 'subCategory', 'articleType', 'season', 'usage']]
product_re = product_re.rename({"id" : "product_id"} ,axis = "columns")
product_re = product_re.rename({"masterCategory" : "ctgr1"} ,axis = "columns")
product_re = product_re.rename({"subCategory" : "ctgr2"} ,axis = "columns")
product_re = product_re.rename({"articleType" : "type"} ,axis = "columns")
product_f = product_re
#customer 데이터 컬럼명 수정 및 필요 컬럼만 정리
customer_re = customer[['customer_id', 'gender', 'home_country', 'first_join_date', 'birthdate']]
customer_re["first_join_date"] = pd.to_datetime(customer_re["first_join_date"])
customer_re["birthdate"] = pd.to_datetime(customer_re["birthdate"])
customer_re["first_dt(bool)"] = customer_re["first_join_date"].dt.strftime("%Y-%m-%d")
customer_re["birth_dt_y"] = customer_re["birthdate"].dt.strftime("%Y")
customer_f = customer_re[['customer_id', 'gender', 'home_country', 'first_dt(bool)', 'birth_dt_y']]
#고객별 나이 구하기
customer_f["birth_dt_y"] = customer_f["birth_dt_y"].astype(int)
customer_f['age'] = 2024 - customer_f["birth_dt_y"]
#고객 연령대 컬럼 추가
def agerange(row):
age = row["age"]
if age < 10:
return "10세 미만"
if (age >= 10) and (age < 20):
return "10대"
if (age >= 20) and (age < 30):
return "20대"
if (age >= 30) and (age < 40):
return "30대"
if (age >= 40) and (age < 50):
return "40대"
if (age >= 50) and (age < 60):
return "50대"
if (age >= 60) and (age < 100):
return "60대 이상"
else:
return "기타"
customer_f["range"] = customer_f.apply(agerange, axis = "columns")
customer_f.head()

#데이터 프레임 합치기
order_p = pd.merge(order_f, product_f, on = "product_id", how = "left")
merge = pd.merge(order_p, customer_f, on = "customer_id" , how = "left")
#null값 확인 후 제외
merge.isnull().sum()
merge_na = merge.dropna(axis = 0)
-군집화 변수로 usage 지정하고자 null 값 제외하고 진행
-null 값은 전체 약 6만 건 데이터 중 약 7% 이하이기에 제외하여도 큰 무리없을 것이라 판단

#컬럼별 데이터 탐색 및 변수 지정
pd.concat([merge_na.ctgr1.value_counts(),merge_na.ctgr1.value_counts(normalize=True)], axis = 1)
pd.concat([merge_na.loc[merge_na.ctgr1 == "Apparel", ["ctgr2"]].value_counts(),
merge_na.loc[merge_na.ctgr1 == "Apparel", ["ctgr2"]].value_counts(normalize = True)], axis = 1)
pd.concat([merge_na.loc[merge_na.ctgr1 == "Accessories", ["ctgr2"]].value_counts(),
merge_na.loc[merge_na.ctgr1 == "Accessories", ["ctgr2"]].value_counts(normalize = True)], axis = 1)
pd.concat([merge_na.loc[merge_na.ctgr1 == "Footwear", ["ctgr2"]].value_counts(),
merge_na.loc[merge_na.ctgr1 == "Footwear", ["ctgr2"]].value_counts(normalize = True)], axis = 1)
pd.concat([merge_na.usage.value_counts(), merge_na.usage.value_counts(normalize = True)], axis = 1)
pd.concat([merge_na.season.value_counts(), merge_na.season.value_counts(normalize = True)], axis = 1)
merge_na.gender.value_counts()
merge_na.range.value_counts()
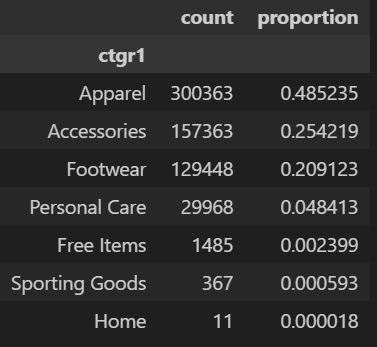
컬럼별로 데이터 비중을 확인하여 변수를 세부 지정한다.
예를 들어 아래 이미지를 보았을 때, 대분류에 속하는 카테고리 ctgr1 에서 Apparel 의 비중이 전체의 약 50%로 높은 편인데 Apparel 하위 카테고리 ctgr2 중에서 특히 topwear 비중이 70% 이상이다. 이 경우 Apparel 하나를 통으로 변수로 지정하지 않고, top wear, bottom wear, innerwear, etc 로 Apparel를 4개로 쪼개어 변수를 지정할 수 있다.

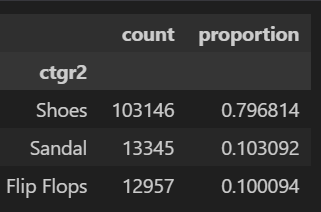
아래는 footwear 의 하위카테고리 데이터이다. footwear 는 전체 20% 비중을 차지하고 있어 큰 비중이라 보기 어렵고, 세부 카테고리 또한 큰 의미를 두기 어렵다 판단하여 이 경우 footwear를 통으로 변수 지정한다.
[최종 변수 지정]
-Apparel : top wear / bottom wear / inner wear / etc 3가지 구분
-Accessories : 단일 처리
-footwear : 단일 처리
-season : summer / fall / winter / spring 구분
-gender : 남자/여자 구분
-range : 10대 이하 / 20대 / 30대 / 40대 이상 구분
위에서처럼 변수를 지정할 때 카테고리별 중요도를 판단해야하는데 이때 마케터가 어떤 가설을 가지고 있는 지가 굉장히 중요하다. 여름과 겨울 시즌 구매 상품 종류 달라지므로 계절을 넣겠다, 연령대별/성별별 구매 패턴이 다르므로 연령대, 성별을 변수로 지정하겠다 등의 대략적인 판단이 있어야 한다. 그래야 위와 같이 카테고리 중에서도 어떤 카테고리를 넣을 지, 뺄 지에 대한 결정을 할 수 있다.
마케터가 어떤 결과를 예상하고 변수를 지정하느냐가 (뒤에 나오겠지만)결과에 대한 해석에도 영향을 미치기에 변수를 지정하는 과정이 전체 과정 중에서 가장 중요하다고 생각한다.
kaggle 샘플 데이터로 진행되기에 나는 일단 유의미한 변수를 모두 지정하고 결과에 따라 변수 조합을 변경하며 최적의 결과를 찾아나가는 방식으로 가고자 한다.
#변수 지정에 따라 데이터 정리
#고객별 구매건 수
order_cnt_peruser = merge_na.groupby("customer_id").agg( order_cnt = ("order_date(bool)", "count") )
order_cnt_peruser
#Apparel : top / bottom / inner 3가지 구분
apparel_top = merge_na[(merge_na.ctgr1 == "Apparel") & (merge_na.ctgr2 == "Topwear")].groupby("customer_id")["ctgr2"].count()
apparel_bottom = merge_na[(merge_na.ctgr1 == "Apparel") & (merge_na.ctgr2 == "Bottomwear")].groupby("customer_id")["ctgr2"].count()
apparel_inner = merge_na[(merge_na.ctgr1 == "Apparel") & (merge_na.ctgr2 == "Innerwear")].groupby("customer_id")["ctgr2"].count()
apparel_etc = merge_na[(merge_na.ctgr1 == "Apparel") & ~(merge_na.ctgr2 == "Innerwear")& ~(merge_na.ctgr2 == "Bottomwear")& ~(merge_na.ctgr2 == "Topwear")].groupby("customer_id")["ctgr2"].count()
#season : summer, fall, winter, spring 구분
season_spring = merge_na[merge_na.season == "Spring" ].groupby("customer_id")["season"].count()
season_summer = merge_na[merge_na.season == "Summer" ].groupby("customer_id")["season"].count()
season_fall = merge_na[merge_na.season == "Fall" ].groupby("customer_id")["season"].count()
season_winter = merge_na[merge_na.season == "Winter" ].groupby("customer_id")["season"].count()
# Accessories : 단일 처리
# footwear : 단일 처리
acc = merge_na[merge_na.ctgr1 == "Accessories"].groupby("customer_id")["ctgr2"].count()
foot = merge_na[merge_na.ctgr1 == "Footwear"].groupby("customer_id")["ctgr2"].count()
# 성별 남/여 각각 단일 처리
gender_f = merge_na[merge_na.gender == "F" ].groupby("customer_id")["gender"].count()
gender_m = merge_na[merge_na.gender == "M" ].groupby("customer_id")["gender"].count()
# 연령대 단일 처리
range_below10 = merge_na[(merge_na.range == "10세 미만") | (merge_na.range == "10대") ].groupby("customer_id")["range"].count()
range_20 = merge_na[merge_na.range == "20대" ].groupby("customer_id")["range"].count()
range_30 = merge_na[merge_na.range == "30대" ].groupby("customer_id")["range"].count()
range_more40 = merge_na[(merge_na.range == "40대") | (merge_na.range == "50대") | (merge_na.range == "60대 이상") ].groupby("customer_id")["range"].count()
#변수명 지정
apparel_top = apparel_top.to_frame().reset_index().rename(columns = {'ctgr2':'apparel_top'})
apparel_bottom = apparel_bottom.to_frame().reset_index().rename(columns = {'ctgr2':'apparel_bottom'})
apparel_inner = apparel_inner.to_frame().reset_index().rename(columns = {'ctgr2':'apparel_inner'})
apparel_etc = apparel_etc.to_frame().reset_index().rename(columns = {'ctgr2':'apparel_etc'})
acc = acc.to_frame().reset_index().rename(columns = {'ctgr2':'acc'})
foot = foot.to_frame().reset_index().rename(columns = {'ctgr2':'foot'})
season_spring = season_spring.to_frame().reset_index().rename(columns = {'season':'season_spring'})
season_summer = season_summer.to_frame().reset_index().rename(columns = {'season':'season_summer'})
season_fall = season_fall.to_frame().reset_index().rename(columns = {'season':'season_fall'})
season_winter = season_winter.to_frame().reset_index().rename(columns = {'season':'season_winter'})
gender_f = gender_f.to_frame().reset_index().rename(columns = {'gender':'gender_f'})
gender_m = gender_m.to_frame().reset_index().rename(columns = {'gender':'gender_m'})
range_below10 = range_below10.to_frame().reset_index().rename(columns = {'range':'range_below10'})
range_20 = range_20.to_frame().reset_index().rename(columns = {'range':'range_20'})
range_30 = range_30.to_frame().reset_index().rename(columns = {'range':'range_30'})
range_more40 = range_more40.to_frame().reset_index().rename(columns = {'range':'range_more40'})
#데이터 통합
merge_all = pd.merge(order_cnt_peruser,apparel_top, how ='left', on = 'customer_id' )
merge_all1 = pd.merge(merge_all,apparel_bottom, how ='left', on = 'customer_id' )
merge_all2 = pd.merge(merge_all1,apparel_inner, how ='left', on = 'customer_id' )
merge_all3 = pd.merge(merge_all2,acc, how ='left', on = 'customer_id' )
merge_all4 = pd.merge(merge_all3,foot, how ='left', on = 'customer_id' )
merge_all5 = pd.merge(merge_all4,season_spring, how ='left', on = 'customer_id' )
merge_all6 = pd.merge(merge_all5,season_summer, how ='left', on = 'customer_id' )
merge_all7 = pd.merge(merge_all6,season_fall, how ='left', on = 'customer_id' )
merge_all8 = pd.merge(merge_all7,season_winter, how ='left', on = 'customer_id' )
merge_all9 = pd.merge(merge_all8,gender_f, how ='left', on = 'customer_id' )
merge_all10 = pd.merge(merge_all9,gender_m, how ='left', on = 'customer_id' )
merge_all11 = pd.merge(merge_all10,range_below10, how ='left', on = 'customer_id' )
merge_all12 = pd.merge(merge_all11,range_20, how ='left', on = 'customer_id' )
merge_all13 = pd.merge(merge_all12,range_30, how ='left', on = 'customer_id' )
merge_all_f = pd.merge(merge_all13,range_more40, how ='left', on = 'customer_id' )
merge_all_f.fillna(0, inplace = True)

#이상치 확인 및 정리
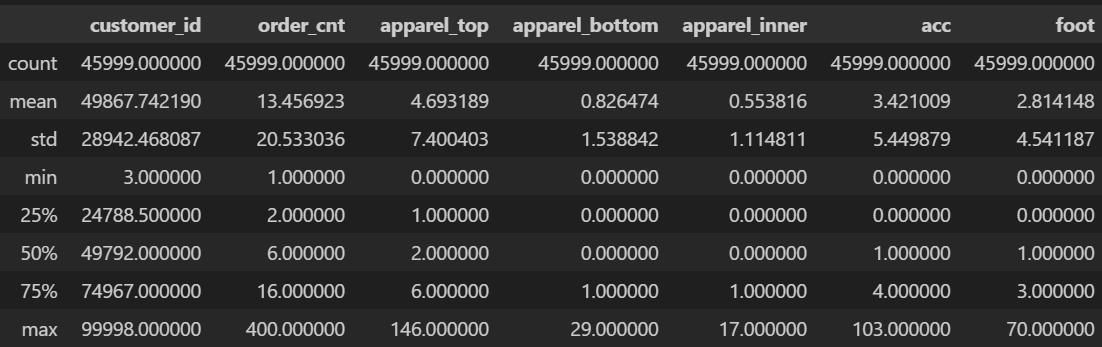
merge_all_f.describe()
import matplotlib.pyplot as plt
import seaborn as sns
target = merge_all_f["apparel_top"]
sns.scatterplot(data=target)
sns.displot(merge_all_f["apparel_top"])
#이상치 판단 기준 잡기
merge_all_f[(merge_all_f["apparel_top"] >= 50)]["customer_id"].count()
print("표준편차 :", merge_all_f["apparel_top"].std())
print("99분위수 :", merge_all_f["apparel_top"].quantile(q =0.99), ", 대상자수 : ",merge_all_f[merge_all_f["apparel_top"]>= 36]['customer_id'].count())
print("3시그마 :", (merge_all_f["apparel_top"].mean()) + (merge_all_f["apparel_top"].std()*3), ", 대상자수 : ",merge_all_f[merge_all_f["apparel_top"]>= 27]['customer_id'].count())
print("6시그마 :", (merge_all_f["apparel_top"].mean()) + (merge_all_f["apparel_top"].std()*6), ", 대상자수 : ",merge_all_f[merge_all_f["apparel_top"]>= 49]['customer_id'].count())
#최종
merge_all_ff = merge_all_f[(merge_all_f["apparel_top"] < 35) & (merge_all_f["acc"] < 26)]
변수별 이상치를 확인한다. apparel_top, acc(악세사리)의 경우 평균값과 최대값 간극이 비정상적으로 큰 편이다.
displot을 통해 데이터 분포를 확인하고 scatterplot을 통해 이상치 분포도 같이 확인하였다. 정확한 이상치 제외를 위해 표준편차를 이용했다.
apparel_top, acc(악세사리) 둘 다 같은 방식을 이용하여 이상치를 제외하였다.
#군집화 진행
merge_all_ff = merge_all_ff.reset_index()
#변수 표준화
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(merge_all_ff.iloc[:,2:])
np_train_scaled = scaler.transform(merge_all_ff.iloc[:,2:])
np_train_scaled
kmeans = KMeans(n_clusters=6)
y_pred = kmeans.fit_predict(np_train_scaled)
kmeans.cluster_centers_
# 최적의 cluster 개수 찾기
kmeans_per_k = [KMeans(n_clusters=k).fit(np_train_scaled) for k in range(1, 10)]
inertias = [model.inertia_ for model in kmeans_per_k]
plt.figure(figsize=(8, 3.5))
plt.plot(range(1, 10), inertias, "bo-")
plt.show()
최적의 클러스터 개수를 찾기 위해 아래 그래프를 보았을 때 팔꿈치처럼 딱 꺾이는 부분이 3임을 알 수 있다. 변수 지정할 때 특정 카테고리, 특정 시즌에 데이터가 집중되는 경향을 보여서 군집이 다양하게 나뉘지 못한 것으로 보인다
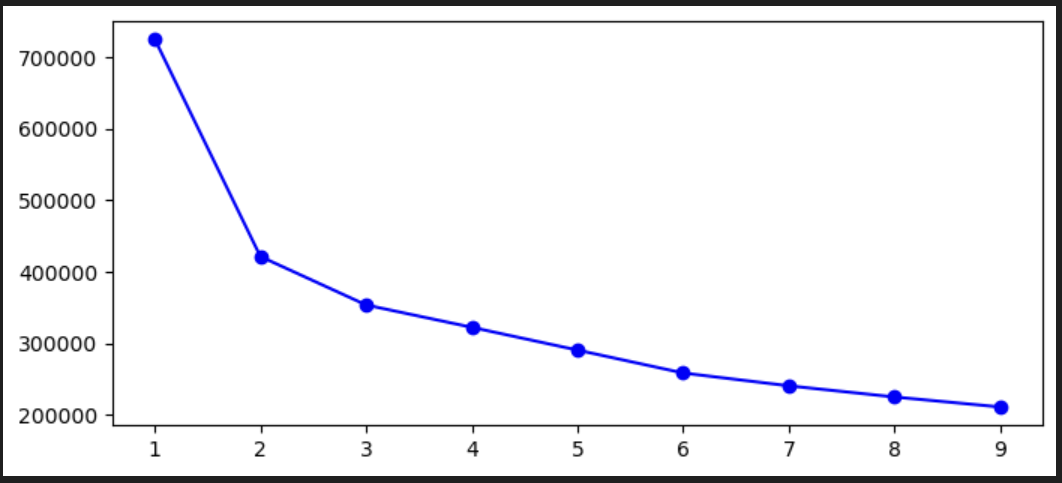
2개 군집은 사실...해석에 의미가 없으므로 일단 4개 군집으로 나눠본다.
#4개 군집으로 나누기
kmeans = KMeans(n_clusters=4, random_state = 1111)
y_pred = kmeans.fit_predict(np_train_scaled)
kmeans.cluster_centers_
y_pred
pd.DataFrame(y_pred)
merge_all_ff['clst_k4'] = pd.Series(y_pred)
merge_all_ff.head()
merge_all_ff.groupby('clst_k4').agg(
cnt_customer = ('customer_id','count'),
avg_order_cnt = ('order_cnt','mean'),
apparel_top_avg = ('apparel_top','mean'),
apparel_bottom_avg = ('apparel_bottom','mean'),
apparel_inner_avg = ('apparel_inner','mean'),
acc_avg = ('acc','mean'),
foot_avg = ('foot','mean'),
season_spring_avg = ('season_spring','mean'),
season_summer_avg = ('season_summer','mean'),
season_fall_avg = ('season_fall','mean'),
season_winter_avg = ('season_winter','mean'),
gender_f_avg = ('gender_f','mean'),
gender_m_avg = ('gender_m','mean'),
range_below10_avg = ('range_below10','mean'),
range_20_avg = ('range_20','mean'),
range_30_avg = ('range_30','mean'),
range_more40_avg = ('range_more40','mean'))
최종 결과 표이다.
(변수 지정할 때부터 알 수 있지만 데이터 쏠림이 심했는데 역시..결과에도 그게 그대로 반영이 되었다..ㅠ)


결과를 해석하는 것은 분석하는 마케터의 역량이라 생각한다.
클러스터링 분석을 할 때 처음 지정한 변수대로 좋은 결과가 나오면 좋지만 대부분은 여러 번 변수 조합을 하면서 유의미한 결과를 찾아나가는 힘겨운 과정이 동반된다...^^... (예를 들어 season 변수를 제외하고 가격대를 고가/저가로 분류하여 변수를 추가해본다던 지..)
고객 클러스터링 분석은 여러 변수를 통해 고객을 관심사별로 분류할 수 있기에 crm 캠페인을 진행할 때 여기서 나온 결과를 관련성 높은 메세지를 보내 유입과 구매전환율을 높이는 시도를 해볼 수 있다.
예를 들어 나이키, 뉴발란스와 같은 특정 브랜드를 선호하는 고객이라면 해당 브랜드의 신상이나 특가 소식을 전했을 때 구매전환율이 높아질 가능성이 높을 수 밖에 없다. 다만 이 경우 크로스셀링/업셀링 관점에서 고민이 들 수 밖에 없다. (모든 이커머스의 고민이 아닐까 생각한다.)
이건 "구매 연관성 분석"을 통해 해결해볼 수 있다.
[구매연관성 분석 관련글]
| [crm/마케팅분석] 구매연관성 분석 어떻게 활용할까? | https://ironyoo.tistory.com/10 |
| [crm/데이터분석] 파이썬으로 구매연관성 분석하 | https://ironyoo.tistory.com/11 |
'Data analysis > Data marketing' 카테고리의 다른 글
| [crm/데이터분석] 파이썬으로 구매연관성 분석하기 (0) | 2024.03.17 |
|---|