이번 글에서는 파이썬으로 직접 구매연관성 분석을 해보겠습니다.
구매연관성 분석이 뭔지, 마케팅에서 어떻게 활용되는 지에 대한 이야기는 별도 글로 작성해두었습니다.
▼ ▼
| [crm/마케팅분석] 구매연관성 분석 어떻게 활용할까? | https://ironyoo.tistory.com/10 |
*분석언어: 파이썬
*알고리즘: fpgrowth
*데이터: (kaggle제공) transaction data 링크
Transaction Data
Costumer segmentation
www.kaggle.com
우선 필요한 라이브러리를 호출하고, 데이터 정제 작업을 해보겠습니다.
#필요한 라이브러리 호출
import pandas as pd
import numpy as np
import datetime as dt
#데이터 불러오기
order = pd.read_csv("C:/Users/.../transaction_data.CSV")
#컬럼명/날짜 데이터 정리
order = order.rename({"UserId" : "user_id"} ,axis = "columns")
order = order.rename({"TransactionId" : "invoice_id"} ,axis = "columns")
order = order.rename({"TransactionTime" : "order_date"} ,axis = "columns")
order = order.rename({"ItemCode" : "product_id"} ,axis = "columns")
order = order.rename({"NumberOfItemsPurchased" : "quantity"} ,axis = "columns")
order = order.rename({"CostPerItem" : "price"} ,axis = "columns")
order = order.rename({"Country" : "country"} ,axis = "columns")
order = order.rename({"ItemDescription" : "product"} ,axis = "columns")
order["order_date"] = pd.to_datetime(order["order_date"])
order["order_date_d"] = order["order_date"].dt.strftime("%Y-%m-%d")
order["order_date_m"] = order["order_date"].dt.strftime("%Y-%m")
order["order_date_y"] = order["order_date"].dt.strftime("%Y")
#날짜에 2018 / 2019 / 2028 연도로 구성되어있어 2028년도 데이터는 제외
order_f = order[order["order_date_y"] != "2028"]
order_f["order_date_y"].value_counts()
▼최종 정리된 데이터

데이터 이상치 여부를 확인하고 제거하는 작업을 하겠습니다. 평균값, 중앙값과 max 값을 비교했을 때 크게 튀는 수치가 있는지, null값이 있는 지 등을 파악합니다.
#데이터 이상치 여부 확인
order_f.describe()
#null값 여부 확인
order_f.isnull().sum()
# product컬럼 Null값 제외 & 음수값 제외
order_f_c = order_f[order_f["product"].notnull()]
order_f_c = order_f[(order_f["user_id"] > 0) & (order_f["quantity"] > 0) & (order_f["product_id"] > 0)]
▼user_id / product_id / quantity / price 값 음수 존재 (환불처리된 데이터로 예상)

▼product 컬럼에 null 값 다수 존재
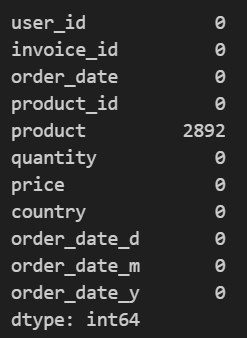
product 컬럼은 구매연관성 분석 시 중요 변수이기에 null값은 제외했습니다.
(null 값 데이터 = 전체 100만 개 데이터 중 3% 비중)
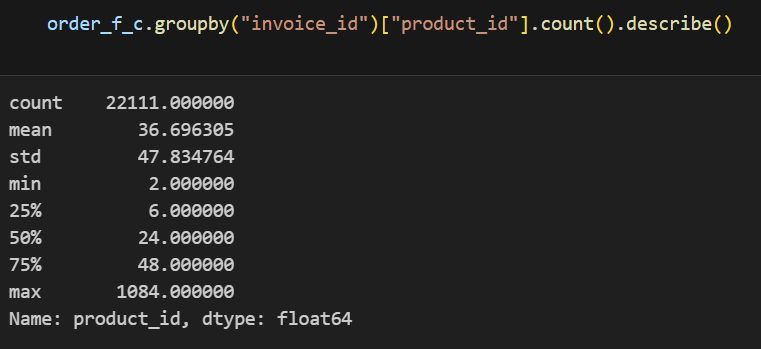
인보이스당 상품 구매 수를 확인하겠습니다. 동시에 A와 B 상품을 구매해도 각각 다른 인보이스가 발급되는 경우도 있어 인보이스 발급 기준을 확인하고 거래 단위 기준을 잡는 목적입니다
#거래 단위 확인_인보이스당 상품 구매 건 수 확인
order_f_c.groupby("invoice_id")["product_id"].count().describe()
#거래 단위 확인_유저당 인보이스 수 확인
order_f_c.groupby("user_id")["invoice_id"].nunique().describe()
#고객당 일별 구매 인보이스 수 확인
order_f_c.groupby(["user_id", "order_date"])["invoice_id"].nunique().describe()
#인보이스 / 상품ID 기준으로 진행
invoice_cnt = order_f_c.groupby("invoice_id").agg(
n = ("product_id", "count"))
invoice_cnt.columns = ["p_cnt"]
#그래프 활용하여 이상치 추이 확인
import matplotlib.pyplot as plt
import seaborn as sns
fig, ax = plt.subplots()
ax.boxplot(invoice_cnt["p_cnt"])
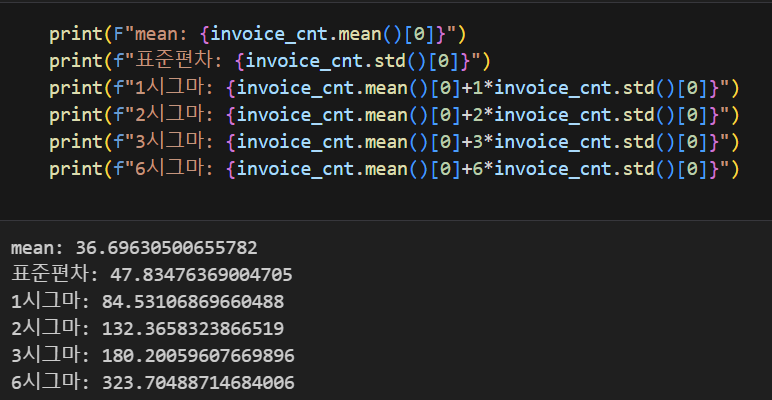
#제외 기준 잡기
print(F"mean: {invoice_cnt.mean()[0]}")
print(f"표준편차: {invoice_cnt.std()[0]}")
print(f"1시그마: {invoice_cnt.mean()[0]+1*invoice_cnt.std()[0]}")
print(f"2시그마: {invoice_cnt.mean()[0]+2*invoice_cnt.std()[0]}")
print(f"3시그마: {invoice_cnt.mean()[0]+3*invoice_cnt.std()[0]}")
print(f"6시그마: {invoice_cnt.mean()[0]+6*invoice_cnt.std()[0]}")
#이상치 제외하고 진행
invoice_cnt_c1 = invoice_cnt[invoice_cnt.p_cnt <= 130]
order_fin = pd.merge(invoice_cnt_c1, order_f_c, how = "inner", on = "invoice_id")
▼인보이스당 구매 상품 건 수
▼고객당 인보이스 수 확인

▼고객당 일별 인보이스 수 확인
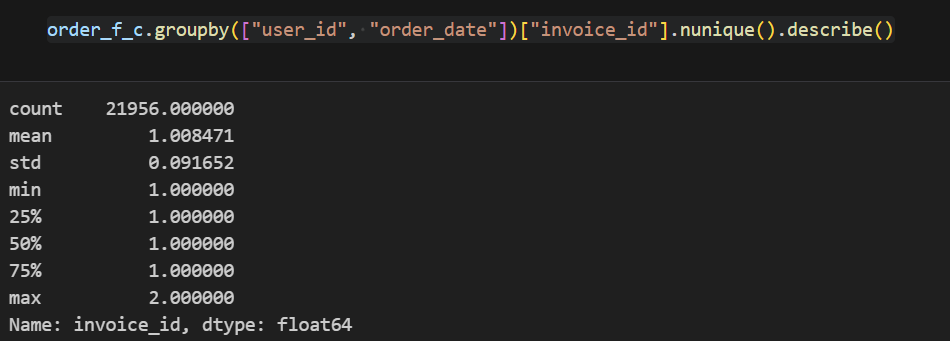
위 내용을 통해 인보이스당 구매 상품 건 수를 기준 단위로 진행해도 되겠다 판단했습니다. 다만 중앙값(47) 대비 MAX값(1084)이 터무니없이 커서 이상치를 제외하고 갔습니다.
▼이상치 제외 기준 잡기
#구매연관성 분석을 위한 라이브러리 호출
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules, fpgrowth
#연관성 분석용 매트릭스 생성_1
order_fin1 = order_fin[['invoice_id', 'product']]
def toList(x):
return list(set(x))
purchase_list = order_fin1.groupby('invoice_id')['product'].apply(lambda x: toList(x)).reset_index()
purchase_list = purchase_list["product"].tolist()
purchase_list[:5]
#연관성 분석용 매트릭스 생성_2
te = TransactionEncoder()
te_ary = te.fit(purchase_list).transform(purchase_list)
df = pd.DataFrame(te_ary, columns=te.columns_)
최소 지지도 기준을 잡아보겠습니다. 1차로는 구매가 많이 일어난 상품을 참고하여 지지도를 잡습니다.
#가장 많이 구매항 상품 top 10 (그래프 확인)
fig, ax = plt.subplots()
order_fin1["product"].value_counts().head(10).plot(ax=ax, kind='bar')
#상품별 전체 구매 비중 확인
order_fin1['product'].value_counts(normalize =True)
▼상품별 전체 구매 비중

잘팔리는 WHITE HANGING HEART T-LIGHT HOLDER이 5% 정도를 차지합니다. 그래서 일단 1%를 최소 지지도로 두고 가겠습니다.
여기서 최소지지도란!
전체 구매 비중이 낮은 것은 제외하고 가는겁니다. 제가 최소 지지도를 1%로 설정하면, 전체 구매 비율이 1% 밑인 상품들은 구매연관성 분석 결과를 보여주지 않습니다.
#최소지지도 확정하기
fpg_1 = fpgrowth(df, min_support = 0.01, max_len = 3, use_colnames = True)
fpg_005 = fpgrowth(df, min_support = 0.005, max_len = 5, use_colnames = True)
위 코드에서 min_support 는 최소 지지도이고, max_len 은 최대 상품 조합 수, use_colnames = True 는 items 이름을 번호가 아닌 이름으로 표시하도록 합니다.
대략 1%로 최소지지도를 잡고, 연관성분석 알고리즘을 적용해 결과를 봅니다.
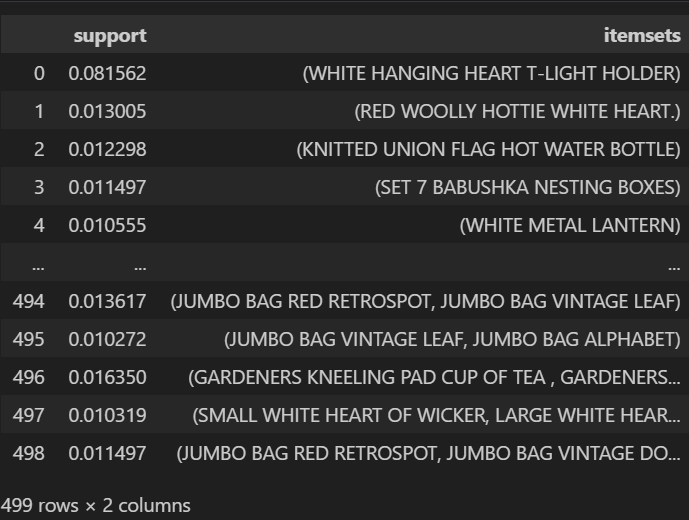
▼최소지지도 1% / 상품 최대 3개 조합일 때
▼최소지지도 0.5% / 상품 최대 5개 조합일 때
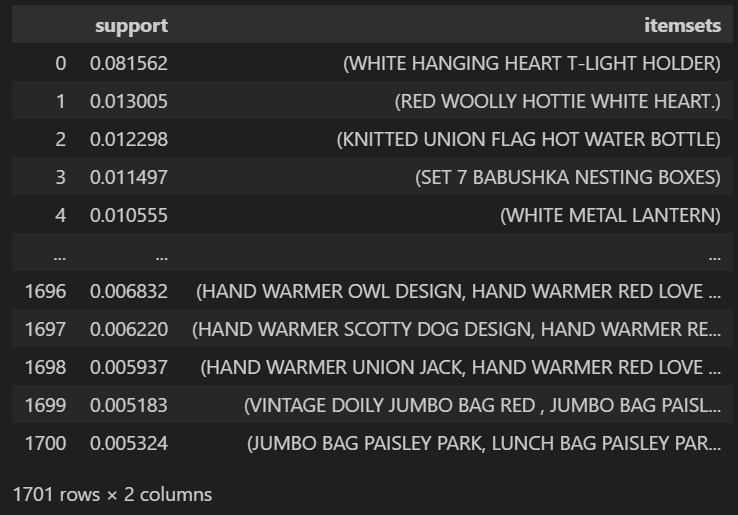
최소지지도 1%, 3개 상품 조합은 결과가 적게 나오는 것 같아 최소지지도 0.5%, 최대 5개 상품 조합으로 진행하겠습니다. 이렇게 최소지지도, 상품조합수를 변경하며 적정 수치를 잡아나갑니다.
참고로 연관분석 알고리즘에는 대표적으로 apriori 알고리즘, FP-growth 알고리즘이 있습니다. 각 알고리즘에 간단히 설명하자면 결과적으로 FP-growth 알고리즘이 apriori 알고리즘의 단점이 될 수 있는 연산 속도를 빠르고 효율적으로 개선한 것이라 보면 됩니다.
apriori 알고리즘은 최소지지도 이하 연관된 상품은 모두 제외하지만 상품 수가 많으면 계산량이 기하급수적으로 늘어나 속도가 느려지는데 FP-growth 알고리즘은 apriori 알고리즘과 같이 최소지지도 이상 아이템만 선택하며 가되 모든 거래에서 빈도가 높은 아이템 순서대로 가기에 연산 속도에서 더 효율적일 수 밖에 없는거죠.
여튼 저는 FP-growth 알고리즘을 사용했습니다.
#최종 결과 확인
fpg_fin = association_rules(fpg_005, metric='confidence', min_threshold=0.5)
fpg_fin.sort_values(['lift'],ascending = False).head(10)
▼최종 결과 리포트
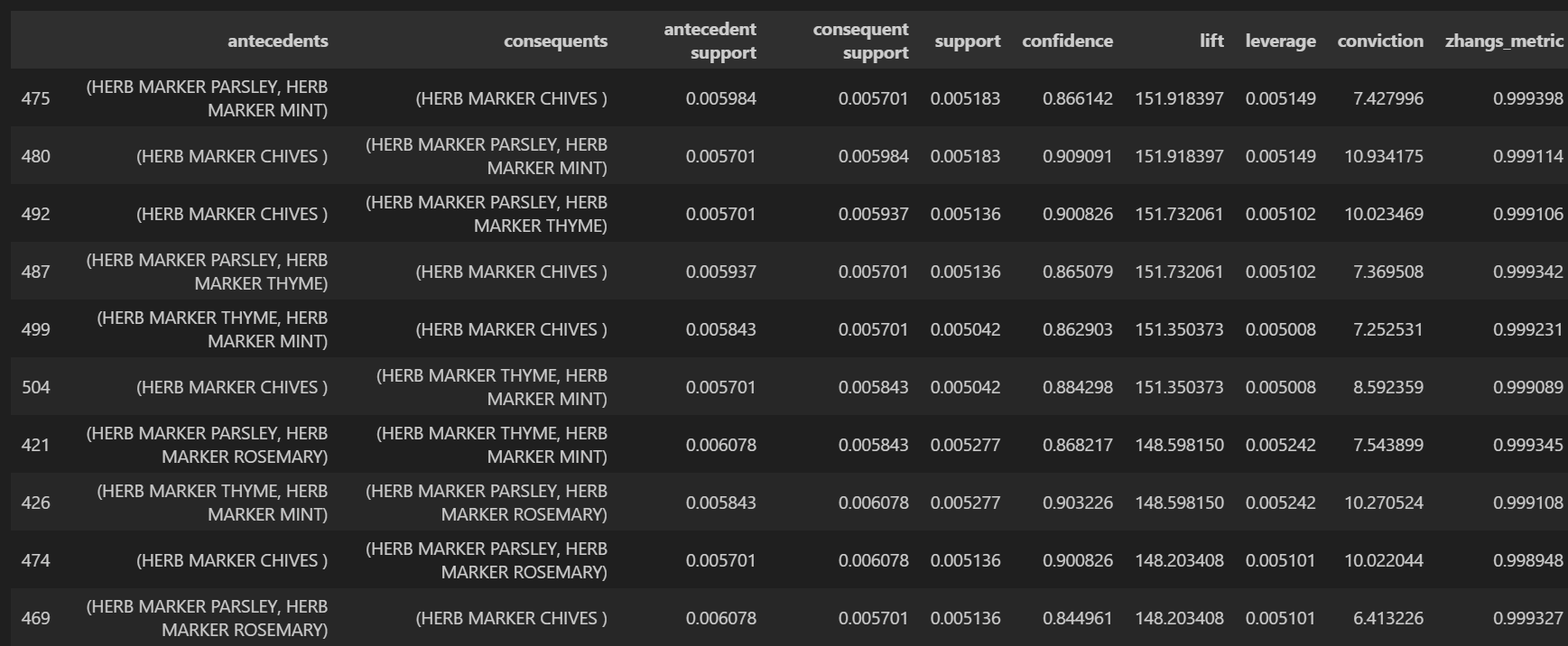
연관성을 파악하기 위해 support, confidence, lift 3가지 주요 지표를 활용합니다. 각 지표별 설명은 아래 링크에 자세히 설명해두었습니다.
▼ ▼
| [crm/마케팅분석] 구매연관성 분석 어떻게 활용할까? | https://ironyoo.tistory.com/10 |
결과가 나온 이후에 결론을 내는 것은 해석하는 담당자의 역량인데요. 저는 개인적으로 support > confidence > lift / leverage 이 순서로 확인합니다.
1) antecedent support로 전체에서 판매 비중이 높은 편인 지 확인 or 목적에 따라 집중 상품 지정(예: 첫구매 이후 재구매를 유도하는 목적이라면 첫구매 중 비중이 높은 상품 위주 확인)
2) confidence 를 통해 A상품을 구매한 고객이 B상품도 구매할 가능성이 높은 지 판단
3) lift 수치를 통해 B상품을 추천 여부 결정 (lift 지표가 헷갈릴 때는 leverage 추가 확인)
파이썬으로 구매연관성 분석을 해보았습니다. 원본 데이터를 통으로 분석하였지만 국가별, 연령/성별을 한정지어서 쪼개어 분석하고 결과를 비교해볼 수도 있습니다.
긴 글 읽어주셔서 감사합니다.
내용에 오류가 있거나 궁금한 부분은 언제든 댓글로 남겨주세요.
좋은 피드백에 대한 댓글은 언제나 환영입니다 :)
'Data analysis > Data marketing' 카테고리의 다른 글
| [crm/데이터분석] 파이썬으로 고객 클러스터링 분석하기 (3) | 2024.03.07 |
|---|